|
I am a final-year Ph.D. student at Institute for Interdisciplinary Information Sciences (IIIS), Tsinghua University, advised by Prof. Yang Gao. Previously, I obtained my bachelor's degree from Beijing University of Posts and Telecommunications (BUPT). My research focuses on Embodied AI, a frontier domain at the intersection of machine learning, robotics and computer vision. I investigate the fundamental challenges of developing general-purpose robotic systems that can effectively adapt and generalize their learned behaviors across diverse, unstructured real-world environments. |

|
|
|
|
Here are representative papers. For more works, please refer to my Google Scholar. |
|
Fanqi Lin*, Ruiqian Nai*, Yingdong Hu*, Jiacheng You, Junming Zhao, Yang Gao International Conference on Learning Representations (ICLR), 2026 project page / arXiv / code / X summary We introduce OneTwoVLA, a single unified vision-language-action model capable of both acting (System One)⚡ and reasoning (System Two)🤔. Importantly, it adaptively determines when to engage each mode. |
|
|
Yingdong Hu*, Fanqi Lin*, Pingyue Sheng, Chuan Wen, Jiacheng You, Yang Gao International Conference on Learning Representations (ICLR), 2025 (Oral Presentation) Best Paper Award at Workshop on X-Embodiment Robot Learning, CoRL 2024 project page / arXiv / code / X summary We demonstrate that the policy’s generalization ability to new objects, new environments, or both scales approximately as a power law with the number of training objects, training environments, or training environment-object pairs, respectively. |
|
|
ByteDance Seed Technical Report, 2025 project page / arXiv GR-3 is a large-scale vision-language-action (VLA) model. It showcases exceptional capabilities in generalizing to novel objects, environments, and instructions involving abstract concepts. |
|
|
Yingdong Hu*, Fanqi Lin*, Tong Zhang, Li Yi, Yang Gao Workshop on Vision-Language Models for Navigation and Manipulation, ICRA 2024 project page / arXiv We introduce ViLa, a novel approach for long-horizon robotic planning that leverages GPT-4V to generate a sequence of actionable steps. ViLa empowers robots to execute complex tasks with a profound understanding of the visual world. |
|
|
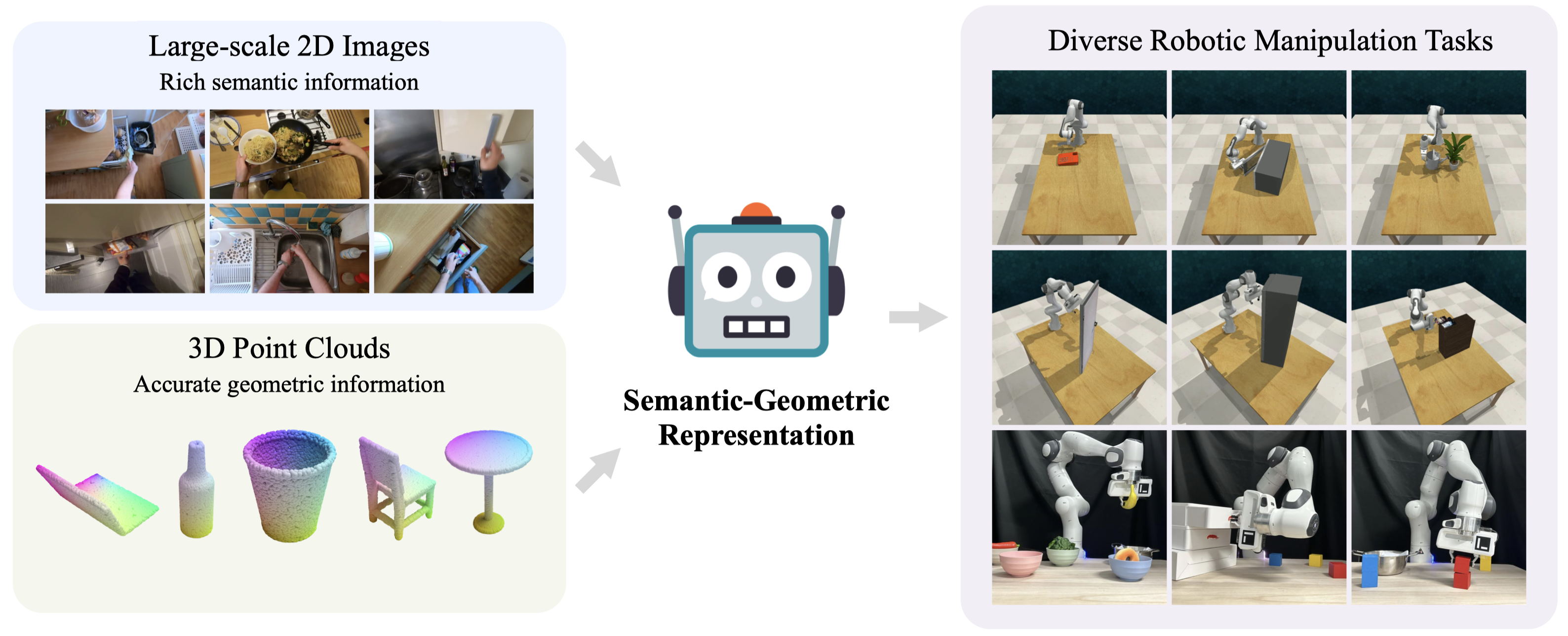
Tong Zhang*, Yingdong Hu*, Hanchen Cui, Hang Zhao, Yang Gao Conference on Robot Learning (CoRL), 2023 project page / arXiv / code We present Semantic-Geometric Representation (SGR), a universal perception module for robotics that leverages the rich semantic information of large-scale pre-trained 2D models and inherits the merits of 3D spatial reasoning. |
|
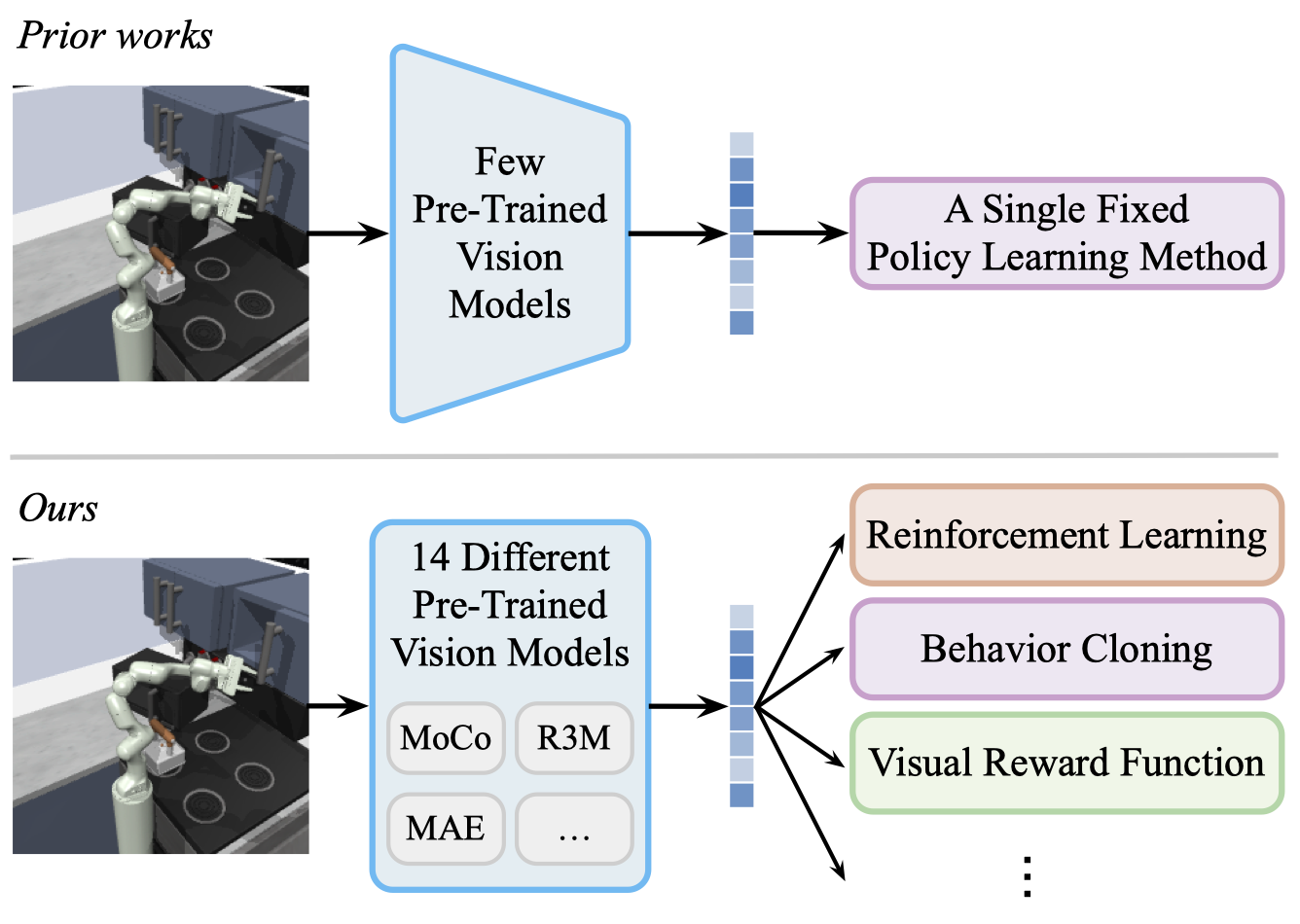
Yingdong Hu, Renhao Wang, Li Erran Li, Yang Gao International Conference on Machine Learning (ICML), 2023 project page / arXiv / code We conduct the first thorough evaluation of pre-trained vision model performance across different downstream policy learning methods and environments. We discover that the effectiveness of pre-training is highly dependent on the choice of the downstream policy learning algorithm. |
|
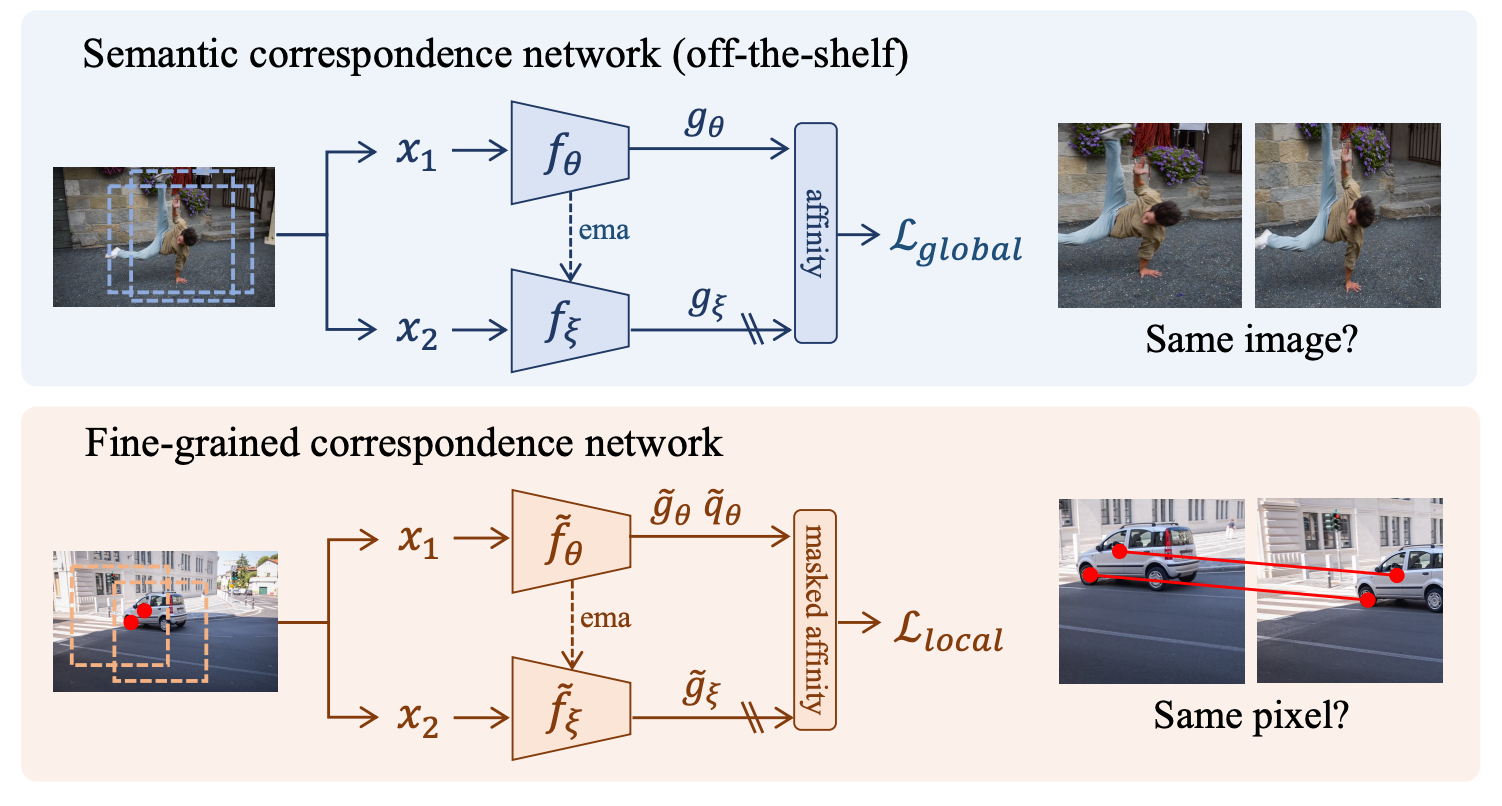
Yingdong Hu, Renhao Wang, Kaifeng Zhang, Yang Gao European Conference on Computer Vision (ECCV), 2022 (Oral Presentation) project page / arXiv / code We show that fine-grained features learned with pixel-level self-supervised learning (SSL) objectives are complementary to semantic features from image-level SSL methods. Fusing these features can significantly improve the performance for visual correspondence tasks. |
|
|
|
Modified from Jon Barron |